Hasta ahora, hemos discutido cómo construir páginas web simples utilizando HTML y CSS, y cómo utilizar Git y GitHub para llevar un registro de los cambios en nuestro código y colaborar con otros. También nos familiarizamos con el lenguaje de programación Python, comenzamos a utilizar Django para crear aplicaciones web y aprendimos a utilizar los modelos de Django para almacenar información en nuestros sitios. Luego introdujimos JavaScript y aprendimos a usarlo para hacer que las páginas web sean más interactivas, y hablamos sobre el uso de animaciones y React para mejorar aún más nuestras interfaces de usuario. Después, hablamos sobre algunas buenas prácticas en el desarrollo de software y algunas tecnologías comúnmente utilizadas para lograr esas mejores prácticas. Hoy, en nuestra última conferencia, discutiremos los problemas de escalar y asegurar nuestras aplicaciones web.
Escalabilidad y Seguridad
Índice
- Introducción
- Escalabilidad
- Escalado
- Equilibrio de carga
- Escalado automático
- Escalado de Base de Datos
- Caché
- Seguridad
- HTML
- HTTPS
- Base de Datos
- Javascript
- ¿Qué es lo que sigue?
Introducción
Escalabilidad
Por el momento, en este curso, hemos construido aplicaciones que se ejecutan solo localmente en nuestras computadoras, pero eventualmente, querremos lanzar nuestros sitios para que puedan ser accesibles por cualquier persona en Internet. Para hacer esto, ejecutamos nuestros sitios en servidores, que son piezas físicas de hardware dedicadas a ejecutar aplicaciones. Los servidores pueden ser locales (poseemos y mantenemos servidores físicos donde se hospeda nuestra aplicación) o en la nube (los servidores son propiedad de una empresa diferente, como Amazon o Google, y pagamos para alquilar espacio en el servidor donde se hospeda nuestra aplicación). Hay ventajas y desventajas en ambas opciones:
- Personalización: Hospedar tus propios servidores te da la capacidad de decidir exactamente cómo funcionan, permitiendo más flexibilidad que el hospedaje en la nube.
- Experiencia: Es mucho más sencillo hospedar una aplicación en la nube que mantener tus propios servidores.
- Costo: Dado que los sitios de hospedaje de servidores necesitan obtener ganancias, te cobrarán más de lo que les cuesta mantener sus servidores locales, lo que hace que los servidores en la nube sean más caros. Sin embargo, los costos iniciales de ejecutar servidores locales pueden ser altos, ya que necesitas comprar servidores físicos y posiblemente contratar a alguien con la experiencia para configurarlos.
- Escalabilidad: Escalar suele ser más fácil cuando se hospeda en la nube. Por ejemplo, si hospedamos un sitio localmente que recibe 500 visitas al día, y luego comienza a recibir 500,000 visitas al día, tendríamos que pedir y configurar más servidores físicos para manejar las solicitudes, y durante ese tiempo muchos de nuestros usuarios no podrían acceder al sitio. La mayoría de los sitios de hospedaje en la nube te permitirán alquilar espacio en el servidor de manera flexible, pagando según la cantidad de actividad que vea tu sitio.
Cuando un usuario envía una solicitud HTTP a este servidor, el servidor debería enviar una respuesta. Sin embargo, en la realidad, la mayoría de los servidores reciben mucho más que una solicitud a la vez, como se muestra a continuación:
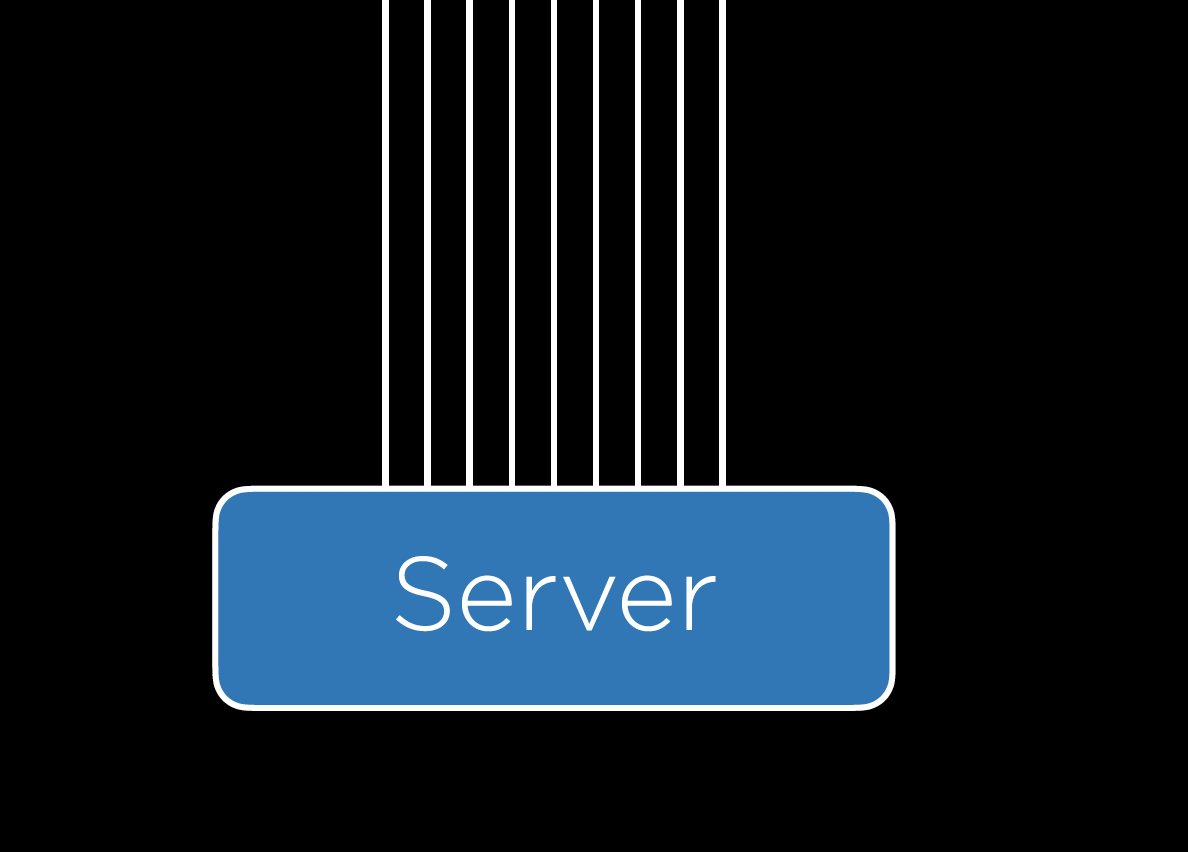
Aquí es donde nos encontramos con el problema de la escalabilidad. Un solo servidor puede manejar solo un número limitado de solicitudes a la vez, lo que nos obliga a hacer planes sobre qué hacer cuando nuestro único servidor está sobrecargado. Ya sea que decidamos hospedarnos localmente o en la nube, tenemos que determinar cuántas solicitudes puede manejar un servidor sin colapsar, lo cual se puede hacer utilizando diversas herramientas de evaluación, incluyendo Apache Bench.
Escalado
Una vez que tenemos un límite superior sobre cuántas solicitudes puede manejar nuestro servidor, podemos comenzar a pensar en cómo queremos abordar la escalabilidad de nuestra aplicación. Dos enfoques diferentes para la escalabilidad incluyen:
- Escalado Vertical: En el escalado vertical, cuando nuestro servidor está sobrecargado, simplemente compramos o construimos un servidor más grande. Sin embargo, esta estrategia tiene limitaciones, ya que hay un límite superior en cuán poderoso puede ser un solo servidor.
- Escalado Horizontal: En el escalado horizontal, cuando nuestro servidor está sobrecargado, compramos o construimos más servidores y luego distribuimos las solicitudes entre nuestros múltiples servidores.
Equilibrio de Carga
Cuando usamos el escalado horizontal, nos enfrentamos al problema adicional de cómo decidimos qué servidores se asignan a qué solicitudes. Respondemos a esa pregunta utilizando un balanceador de carga, que es otro componente de hardware que intercepta las solicitudes entrantes y luego asigna esas solicitudes a uno de nuestros servidores. Hay varios métodos diferentes para decidir qué servidor recibe qué solicitud, pero aquí hay algunos:
- Aleatorio: En este método simple, el balanceador de carga decidirá aleatoriamente a qué servidor asignar una solicitud.
- Round-Robin: En este método, el balanceador de carga alternará qué servidor recibe una solicitud entrante. Si tenemos tres servidores, la primera solicitud podría ir al servidor A, la segunda al servidor B, la tercera al servidor C y la cuarta de nuevo al servidor A.
- Menos Conexiones: En este método, el balanceador de carga busca el servidor que actualmente está manejando menos solicitudes y asigna la solicitud entrante a ese servidor. Esto nos permite asegurarnos de que no estamos sobrecargando un servidor en particular, pero también lleva más tiempo para que el balanceador de carga calcule la cantidad de solicitudes que cada servidor está manejando en comparación con simplemente elegir un servidor al azar.
No hay un método de equilibrio de carga que sea estrictamente mejor que todos los demás métodos, y se utilizan muchos métodos diferentes en la práctica. Un problema que puede surgir al escalar horizontalmente es que podríamos tener sesiones almacenadas en un servidor pero no en otro, y no queremos que los usuarios tengan que volver a ingresar información solo porque el balanceador de carga envía su solicitud a un nuevo servidor. Al igual que con muchos problemas de escalabilidad, hay múltiples enfoques para resolver el problema de las sesiones:
- Sesiones persistentes: Una vez que un usuario visita un sitio, el balanceador de carga recuerda a qué servidor fueron enviados primero y se asegura de enviarlos al mismo. Una gran preocupación con este método es que podríamos terminar con un gran número de usuarios pegados a un solo servidor, provocando que se bloquee.
- Sesiones en la base de datos: Todas las sesiones se almacenan en una base de datos a la que todos los servidores tienen acceso. De esta manera, la información de un usuario estará disponible sin importar a qué servidor se le asigne. La desventaja aquí es que lleva tiempo y potencia de cómputo adicional leer y escribir en una base de datos.
- Sesiones en el lado del cliente: En lugar de almacenar información en nuestros servidores, podemos optar por almacenarla localmente en el navegador web del usuario como cookies. Las desventajas de este método incluyen la preocupación de seguridad de que los usuarios creen cookies falsas que les permitan iniciar sesión como otro usuario, y la preocupación computacional de enviar información de cookies de ida y vuelta con cada solicitud.
Al igual que con el equilibrio de carga, no hay una respuesta única para el problema de las sesiones, y el método que elijas a menudo dependerá de tus circunstancias específicas.
Escalado Automático
Otro problema con el que podríamos encontrarnos es que muchos sitios web son visitados mucho más frecuentemente en ciertos momentos. Por ejemplo, si decidimos lanzar nuestra aplicación "¿Es Año Nuevo?" de antes, podríamos esperar que reciba mucho más tráfico a finales de diciembre hasta principios de enero que en cualquier otro momento del año. Si compramos suficientes servidores para que el sitio permanezca activo durante el invierno, esos servidores estarían inactivos durante el resto del año, desperdiciando espacio y energía. Este escenario ha dado lugar a la idea de autoescalado, que se ha vuelto común en la computación en la nube, donde el número de servidores utilizados por tu sitio puede aumentar y disminuir según la cantidad de solicitudes que recibe. Sin embargo, el autoescalado no es una solución perfecta, ya que lleva tiempo determinar que se necesita un nuevo servidor y lanzar ese servidor. Otro problema potencial es que cuantos más servidores tengas en funcionamiento, más oportunidades hay de que uno falle.
Fallo del servidor
Sin embargo, tener varios servidores puede ayudar a evitar lo que se conoce como un Punto Único de Fallo, que es una pieza de hardware que, después de fallar, causará que todo el sitio se bloquee. Al escalar horizontalmente, el balanceador de carga puede detectar qué servidores han fallado enviando solicitudes periódicas de latido a cada servidor, y luego dejar de asignar nuevas solicitudes a servidores que hayan fallado. En este punto, parece que simplemente hemos trasladado nuestro punto único de falla de un servidor al balanceador de carga, pero podemos tener en cuenta esto teniendo balanceadores de carga de respaldo disponibles si el original llega a fallar.
Escalado de Base de Datos
Además de escalar nuestros servidores que procesan solicitudes, también debemos pensar en maneras de escalar nuestras bases de datos. En este curso utilizamos SQLite, que almacena datos dentro de un archivo en el servidor, pero a medida que almacenamos más y más datos, a veces tiene más sentido almacenar datos en varios archivos diferentes, e incluso en un servidor separado. Esto plantea el problema de qué hacer cuando nuestro servidor de bases de datos ya no puede manejar todas las solicitudes que llegan. Al igual que en otros problemas de escalabilidad, hay varios métodos que podemos usar para mitigar este problema:
- Particionamiento Vertical: Este es un método similar al que usamos al discutir SQL por primera vez, donde dividimos nuestros datos en múltiples tablas diferentes en lugar de tener información redundante en una sola tabla. (Siéntete libre de revisar la conferencia 4 donde dividimos la tabla de vuelos en una tabla de vuelos y una tabla de aeropuertos).
- Particionamiento Horizontal: Este método implica almacenar múltiples tablas con el mismo formato, pero con información diferente. Por ejemplo, podríamos dividir una tabla de vuelos en una tabla de vuelos domésticos y una tabla de vuelos internacionales. De esta manera, cuando deseamos buscar un vuelo de JFK a LHR, no tenemos que perder tiempo buscando en una tabla llena de vuelos domésticos. Una desventaja de este método es que puede ser costoso unir varias tablas una vez que se han dividido.
Replicación de Base de Datos
Incluso después de escalar una base de datos, parece que todavía nos queda un punto único de falla. Si nuestro servidor de bases de datos falla, todos nuestros datos podrían perderse. Así como agregamos más servidores para evitar un punto único de falla, podemos agregar copias de nuestra base de datos para asegurarnos de que el fallo de una base de datos no cierre nuestra aplicación. También, al igual que antes, hay diferentes métodos de replicación de bases de datos, dos de los más populares son:
- Replicación de un Único Primario: En este método hay múltiples bases de datos, pero solo una de ellas se considera la base de datos principal, lo que significa que puedes leer y escribir en una de las bases de datos, pero solo leer en las demás. Cuando la base de datos principal se actualiza, las demás bases de datos se actualizan para coincidir con la principal. Una desventaja de este método es que todavía contiene un punto único de falla cuando se trata de escribir en la base de datos.
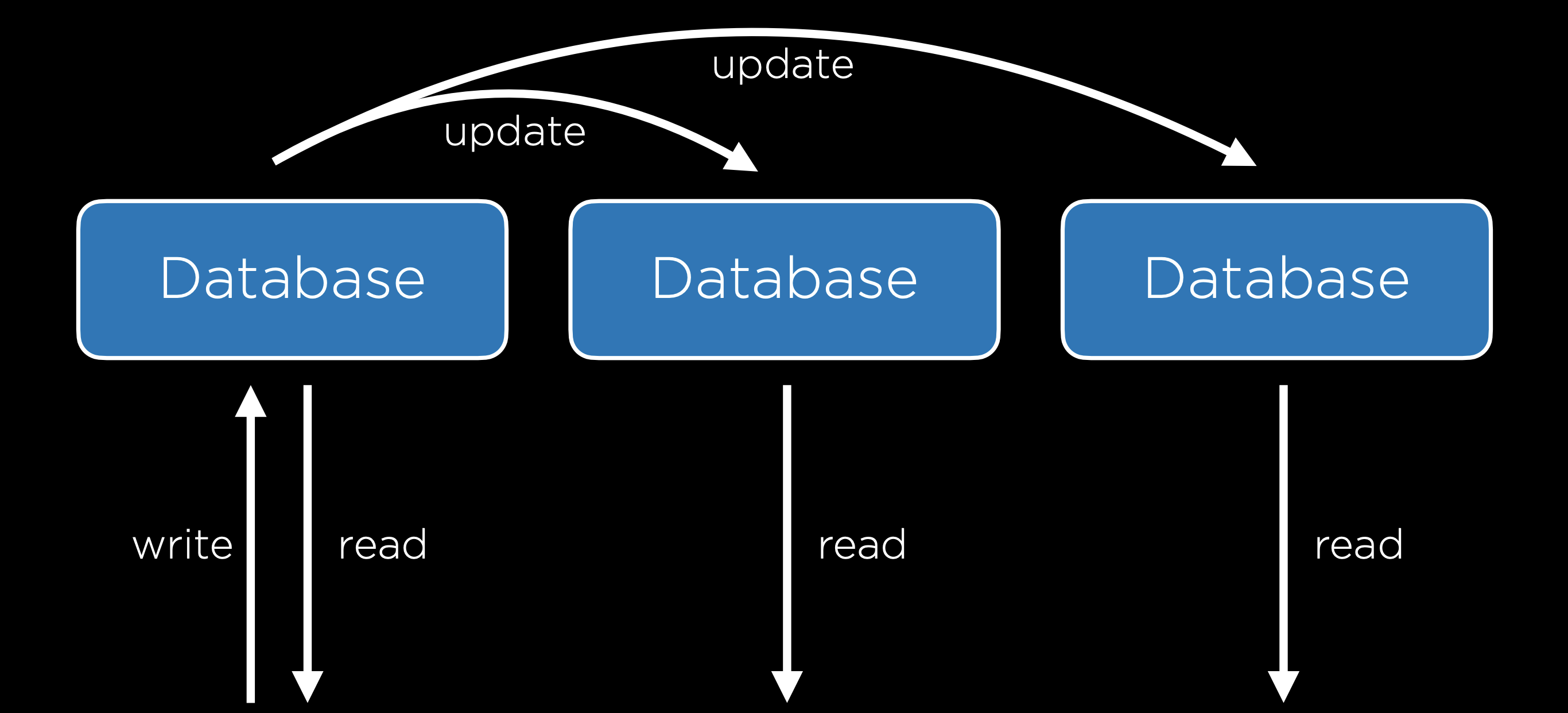
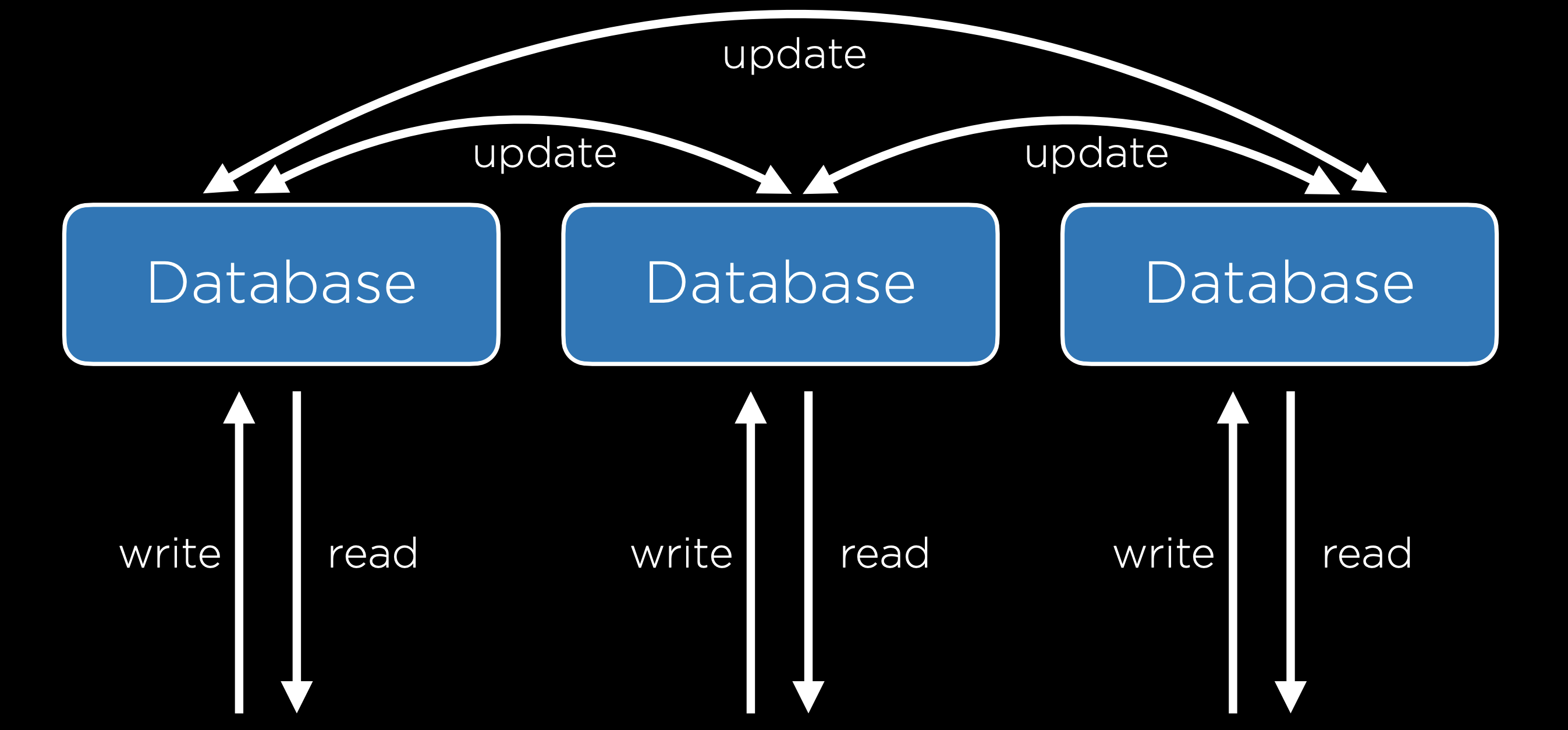
- Replicación de Múltiples Primarios: En este método, todas las bases de datos pueden leerse y escribirse. Esto resuelve el problema de un único punto de falla, pero viene con un intercambio: ahora es mucho más difícil mantener todas las bases de datos actualizadas porque cada base de datos debe estar al tanto de los cambios en todas las demás bases de datos. Este sistema también nos expone a la posibilidad de algunos conflictos:
- Conflicto de Actualización: Con múltiples bases de datos, un usuario puede intentar editar una fila en una base de datos mientras que otro usuario intenta editar esa misma fila en una base de datos diferente, causando un problema cuando las bases de datos se sincronizan.
- Conflicto de Unicidad: Cada fila en una base de datos SQL debe tener un identificador único, y podríamos encontrarnos con el problema de asignar el mismo identificador a dos entradas diferentes en dos bases de datos diferentes.
- Conflicto de Eliminación: Un usuario puede eliminar una fila mientras que otro usuario intenta actualizarla.
Caché
Cuando trabajamos con bases de datos más grandes, es importante reconocer que cada interacción que tenemos con una base de datos tiene un costo. Por lo tanto, deseamos minimizar la cantidad de llamadas a nuestro servidor de bases de datos. Veamos, por ejemplo, el sitio web del New York Times. El New York Times puede tener una base de datos con todos sus artículos, que se consulta y alguna plantilla que se renderiza cada vez que alguien carga la página de inicio, pero esto sería un desperdicio de recursos, ya que es probable que los artículos mostrados en la página de inicio no cambien mucho de segundo a segundo. Una forma de abordar este problema es mediante el uso de la caché, que es la idea de almacenar alguna información en un lugar más accesible si anticipamos que la necesitaremos nuevamente en el futuro cercano.
Una forma en que se puede implementar la caché es almacenando datos en el navegador web del usuario, de modo que cuando un usuario carga ciertas páginas, ni siquiera sea necesario enviar una solicitud al servidor. Una forma de hacer esto es incluir esta línea en el encabezado de una respuesta HTTP:
Cache-Control: max-age=86400
Esto le indicará al navegador que al visitar una página, siempre que haya visitado esa página en los últimos 86400 milisegundos, no es necesario hacer una solicitud al servidor. Este método se utiliza comúnmente en navegadores web, especialmente con archivos que son menos propensos a cambiar en períodos cortos, como un archivo CSS. Para tener un control más preciso sobre este proceso, también podemos agregar unaETagal encabezado de respuesta HTTP, que es una secuencia única de caracteres que representa una versión específica de un documento. Esto es útil porque las solicitudes futuras pueden incluir esta etiqueta y compararla con la etiqueta del último documento en el servidor, solo devolviendo un documento completo cuando ambas etiquetas son diferentes.
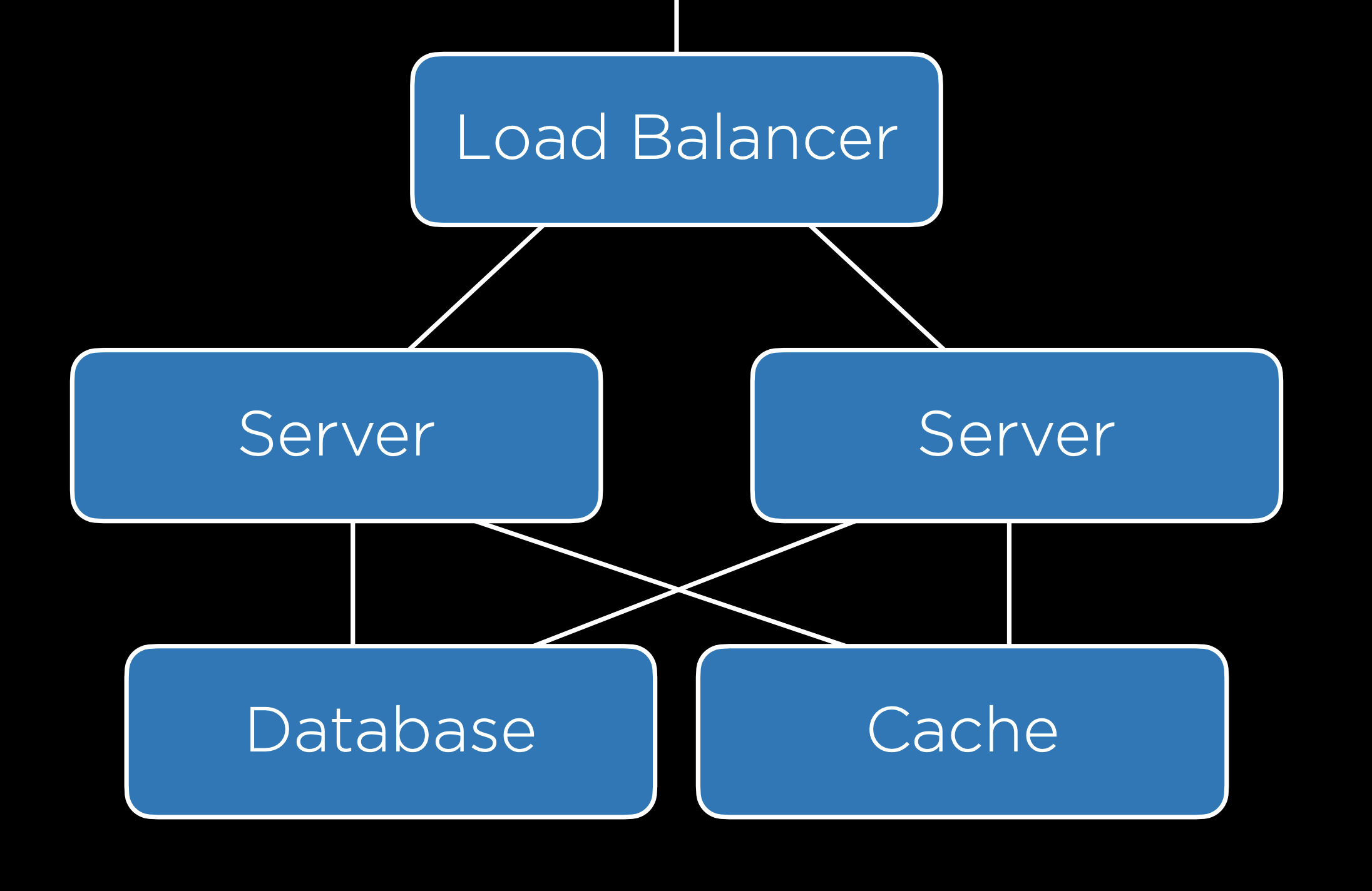
Además del almacenamiento en caché en el lado del cliente discutido anteriormente, a menudo puede ser útil incluir un caché en el lado del servidor. Con este caché, nuestra configuración en el backend se verá un poco como la que se muestra a continuación, donde todos los servidores tienen acceso a una caché. [Imagen: Diagrama con servidores y una caché compartida]
Django proporciona su propiomarco de trabajo de cachéque nos permitirá incorporar el almacenamiento en caché en nuestros proyectos. Este marco ofrece varias formas de implementar una caché:
- Caché por Vista: Esto nos permite decidir que una vez que se ha cargado una vista específica, esa misma vista se puede representar sin pasar por la función durante el próximo período de tiempo especificado.
- Caché de Fragmentos de Plantilla: Esto almacena en caché partes específicas de una plantilla para que no tengan que volver a renderizarse. Por ejemplo, podríamos tener una barra de navegación que cambia raramente, lo que significa que podríamos ahorrar tiempo al no recargarla.
- API de Caché de Bajo Nivel: Esto le permite realizar almacenamiento en caché más flexible, esencialmente almacenando cualquier información que desee.
Aquí no entraremos en detalles sobre cómo implementar el almacenamiento en caché en Django, ¡pero eche un vistazo a ladocumentaciónsi está interesado!
Seguridad
Ahora, comenzaremos a discutir cómo asegurarnos de que nuestras aplicaciones web sean seguras, lo que implicará muchas medidas diferentes que abarcan casi todos los temas que hemos discutido en este curso.
Git y GitHub
Una de las mayores fortalezas de Git y GitHub es lo fácil que hacen compartir y contribuir a software de código abierto, que puede ser visto y contribuido por cualquier persona en Internet. Una desventaja de esto es que si en algún momento confirmas un archivo que incluye credenciales privadas como una contraseña o una clave de API, esas credenciales podrían estar disponibles públicamente.
HTML
Existen muchas vulnerabilidades que surgen al utilizar HTML. Una debilidad común es conocida como un Ataque de Phishing, que ocurre cuando un usuario que cree que va a una página es llevado a otra. Estos no son necesariamente aspectos que podemos tener en cuenta al diseñar un sitio web, pero definitivamente debemos tenerlos en cuenta al interactuar con la web nosotros mismos. Por ejemplo, un usuario malintencionado podría escribir este HTML:
1<!DOCTYPE html>2<html lang="en">3 <head>4 <title>Link</title>5 </head>6 <body>7 <a href="https://solidsnk86.netlify.app/">https://www.teresa-la-implacable.com/</a>8 </body>9</html>Que podría actuar como éste link falso:
El hecho de que HTML se envíe realmente a un usuario como parte de una solicitud abre más vulnerabilidades, porque todos tienen acceso al diseño y estilo que te permitió crear tu sitio. Por ejemplo, un hacker podría ir a bankofamerica.com, copiar todo su HTML y pegarlo en su propio sitio, creando un sitio que se ve exactamente como el de Bank of America. Luego, el hacker podría redirigir el formulario de inicio de sesión en la página para que todos los nombres de usuario y contraseñas se envíen a él. (Además, aquí está el enlace real de Bank of America. ¡Solo quería ver si estabas verificando las URL antes de hacer clic!)
HTTPS
Como discutimos anteriormente en el curso, la mayoría de las interacciones que ocurren en línea siguen el protocolo HTTP, aunque ahora cada vez más transacciones utilizan HTTPS, que es una versión cifrada de HTTP. Mientras se utilizan estos protocolos, la información se transfiere de una computadora a otra a través de una serie de servidores, como se muestra a continuación.
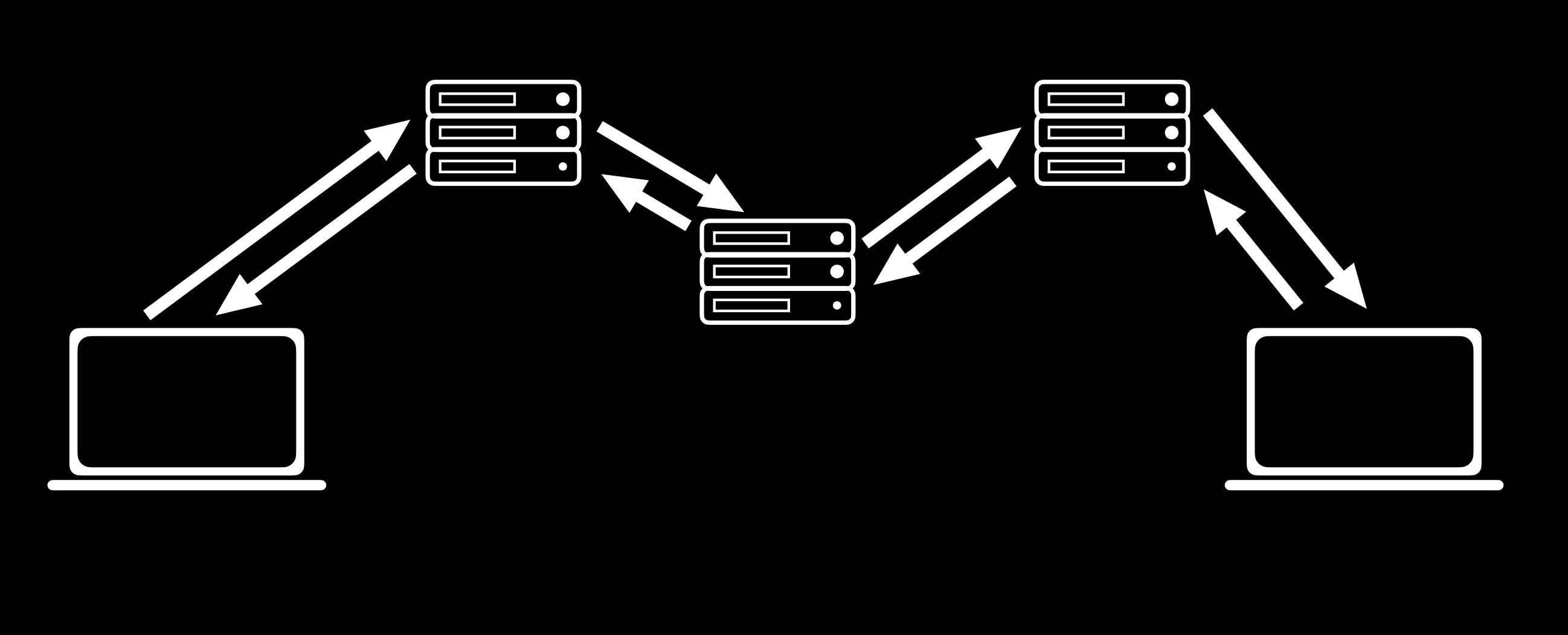
A menudo, no hay forma de asegurar que todas estas transferencias sean seguras, por lo que es importante que toda la información transferida esté cifrada, lo que significa que los caracteres del mensaje se alteran para que el remitente y el destinatario del mensaje puedan entenderlo, pero nadie más.
Cifrado con Clave Secreta
Un enfoque para esto se conoce como cifrado con clave secreta. En este enfoque, el remitente y el destinatario tienen acceso a una clave secreta que solo ellos conocen. Luego, el remitente usa la clave secreta para cifrar un mensaje que luego se envía al destinatario, quien usa la clave secreta para descifrar el mensaje. Este método es extremadamente seguro, pero presenta un gran problema en cuanto a practicidad. Para que funcione, tanto el remitente como el destinatario deben tener acceso a la clave secreta, lo que significa que deben reunirse en persona para intercambiar una clave de forma segura. Con la cantidad de sitios web diferentes con los que interactuamos a diario, está claro que las reuniones en persona no son una opción.
Cifrado con Clave Pública
Un avance increíble en criptografía que permite que internet funcione como lo hace hoy se conoce como cifrado con clave pública. En este método, hay dos claves: una es pública y se puede compartir, y la otra debe mantenerse privada. Una vez que se establecen estas claves (hay varios métodos matemáticos diferentes para crear pares de claves que podrían constituir un curso completo por sí mismos, así que no los discutiremos aquí), un remitente podría buscar la clave pública de un destinatario y usarla para cifrar un mensaje, y luego el destinatario podría usar su clave privada para descifrar el mensaje. Cuando usamos HTTPS en lugar de HTTP, sabemos que nuestra solicitud está siendo segura mediante cifrado con clave pública.
Base de Datos
Además de nuestras solicitudes y respuestas, también debemos asegurarnos de que nuestras bases de datos sean seguras. Una cosa común que necesitaremos almacenar es la información del usuario, incluyendo nombres de usuario y contraseñas, como se muestra en la tabla a continuación:
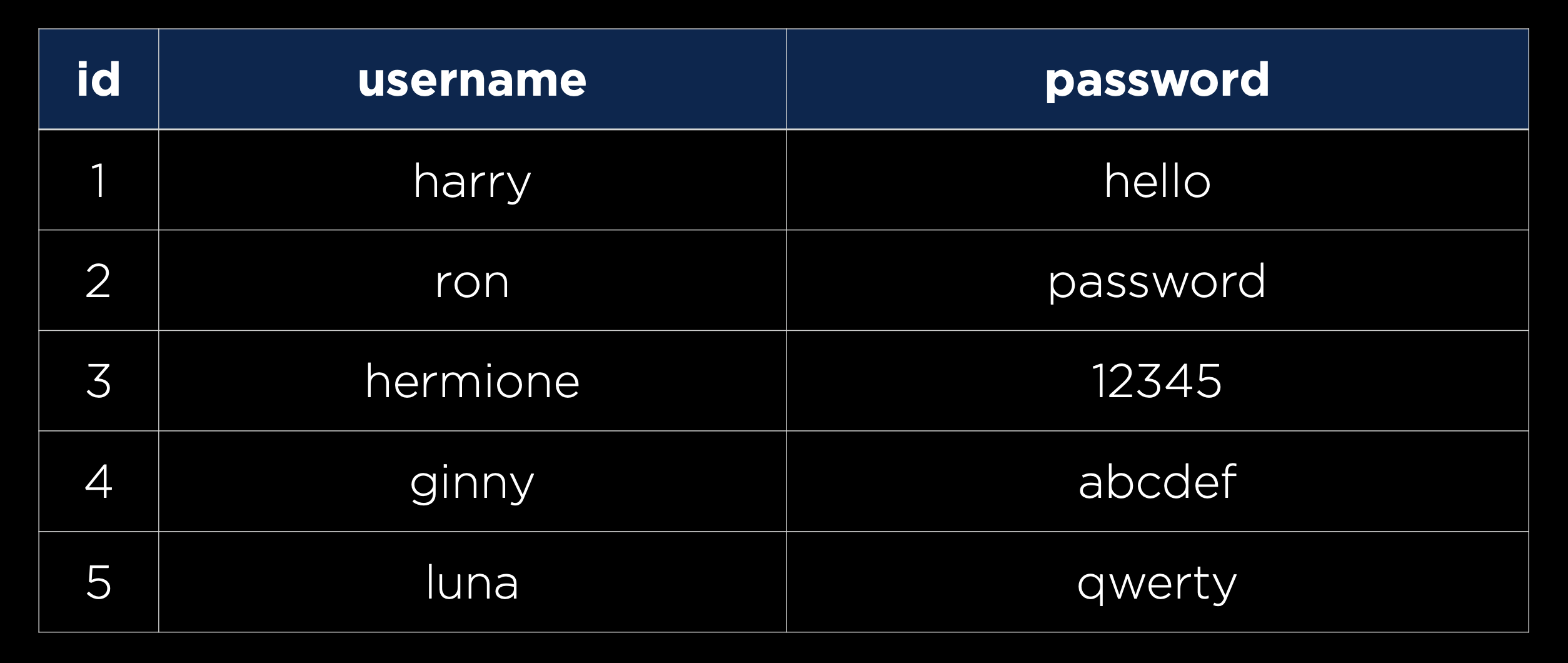
Sin embargo, nunca quieres almacenar contraseñas en texto plano en caso de que una persona no autorizada obtenga acceso a tu base de datos. En su lugar, querremos usar una función hash, una función que toma algún texto como entrada y produce una cadena aparentemente aleatoria como salida, para crear un hash de cada contraseña, como se muestra en la tabla a continuación:

Es importante tener en cuenta que una función hash es unidireccional, lo que significa que puede convertir una contraseña en un hash, pero no puede convertir un hash de nuevo en una contraseña. Esto significa que cualquier empresa que almacene la información del usuario de esta manera en realidad no conoce ninguna de las contraseñas de los usuarios, lo que significa que cada vez que un usuario intenta iniciar sesión, la contraseña ingresada se hasheará y se comparará con el hash existente. Afortunadamente, este proceso ya está gestionado para nosotros por Django. Una implicación de esta técnica de almacenamiento es que cuando un usuario olvida su contraseña, una empresa no tiene forma de decirles cuál es su antigua contraseña, lo que significa que tendrían que crear una nueva.
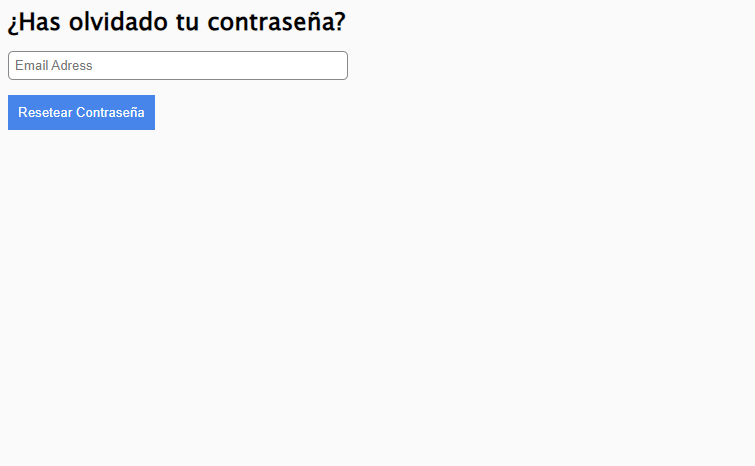
Hay algunos casos en los que tendrás que decidir como desarrollador cuánta información estás dispuesto a filtrar. Por ejemplo, muchos sitios tienen una página para contraseñas olvidadas que se ve así:
Como desarrollador, es posible que desees incluir un mensaje de éxito o error después de la presentación:
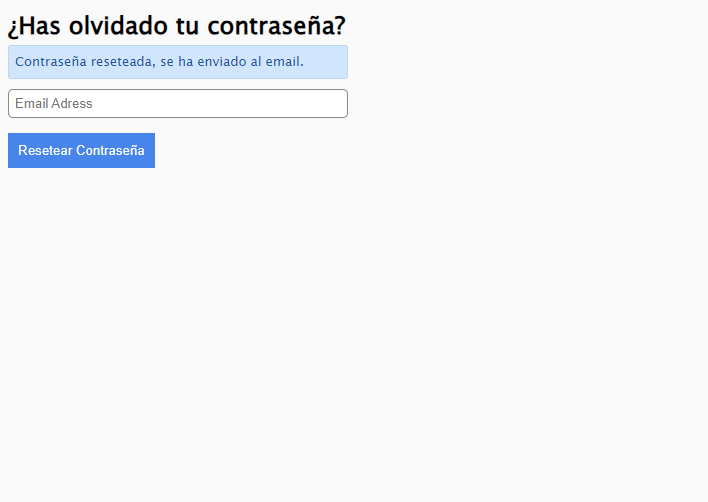
Pero ten en cuenta que al escribir correos electrónicos, cualquiera podría determinar quién tiene un correo electrónico registrado en ese sitio. Esto podría ser totalmente aceptable en casos en los que si una persona usa o no el sitio es inconsecuente (quizás en Facebook), pero extremadamente imprudente si el hecho de que seas miembro de cierto sitio podría poner en peligro tu seguridad (quizás en un grupo de apoyo en línea para víctimas de abuso).
Otra forma en que los datos podrían filtrarse es en el tiempo que tarda en llegar una respuesta. Probablemente tarde menos tiempo en rechazar a alguien con un correo electrónico no válido que a una persona con una dirección de correo electrónico correcta y una contraseña incorrecta.
Como discutimos anteriormente en el curso, debemos tener cuidado con los Ataques de Inyección SQL cada vez que usamos consultas SQL directas en nuestro código.
APIs
A menudo, usamos JavaScript en conjunto con APIs para construir aplicaciones de una sola página. En el caso de que construyamos nuestra propia API, hay algunos métodos que podemos utilizar para mantener segura nuestra API:
- Claves de API: Procesa solo las solicitudes de clientes de la API que tengan una clave que les hayas proporcionado.
- Límite de Tasa: Limita la cantidad de solicitudes que cualquier usuario puede realizar en un período de tiempo dado. Esto ayuda a proteger contra los Ataques de Denegación de Servicio (DOS), en los cuales un usuario malintencionado realiza tantas llamadas a tu API que la hace colapsar.
- Autenticación de Rutas: Hay muchos casos en los que no queremos dar acceso a todos nuestros datos, por lo que podemos usar la autenticación de rutas para asegurarnos de que solo usuarios específicos puedan ver datos específicos.
Variable de Entorno
Así como queremos evitar almacenar contraseñas en texto plano, también querremos evitar incluir claves de API en nuestro código fuente. Una forma común de evitar esto es mediante el uso de variables de entorno, o variables que se almacenan en el entorno de su sistema operativo o servidor. Luego, en lugar de incluir una cadena de texto en nuestro código fuente, podemos incluir una referencia a una variable de entorno.
Javascript
Existen algunos tipos de ataques que los usuarios maliciosos pueden intentar mediante el uso de JavaScript. Un ejemplo es conocido como Cross-Site Scripting (XSS), que ocurre cuando un usuario escribe su propio código JavaScript y lo ejecuta en tu sitio web. Por ejemplo, imaginemos que tenemos una aplicación Django con una única URL:
1urlpatterns = [2 path("<path:path>", views.index, name="index")3]Y con una vista simple deviews.py
1def index(request, path):2return HttpResponse(f"Requested Path: {path}")Este sitio web básicamente le dice al usuario a qué URL han navegado:
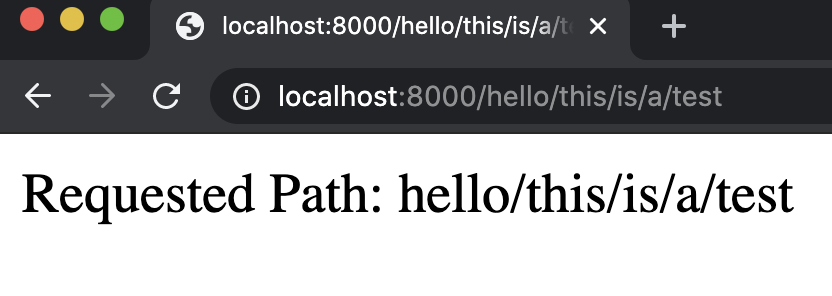
Pero ahora un usuario puede insertar fácilmente algo de JavaScript en la página escribiéndolo en la URL:
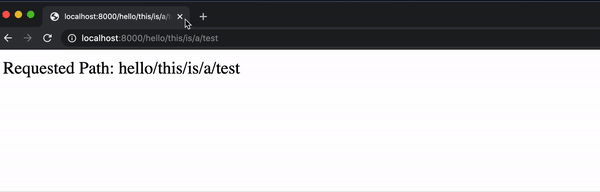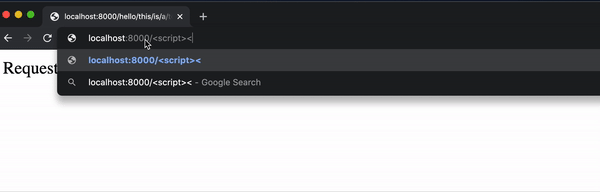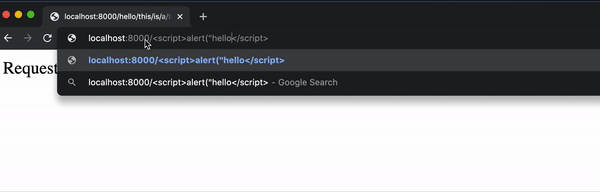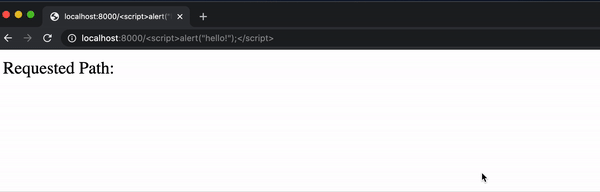
Aunque este ejemplo de alerta es bastante inofensivo, no sería mucho más difícil incluir JavaScript que manipule el DOM o use fetch para enviar una solicitud.
Falsificación de solicitudes entre sitios (CSRF)
Ya discutimos cómo podemos usar Django para prevenir ataques CSRF, pero echemos un vistazo a lo que podría suceder sin esta protección. Como ejemplo, imagina que un banco tiene una URL que podrías visitar para transferir dinero de tu cuenta. Alguien podría crear fácilmente un enlace que realice esta transferencia:
1<a href="http://tubanco.com/transferir?a=neo&amt=2800">2Click Aquí!3</a>Este ataque puede ser aún más sutil que un enlace. Si la URL se coloca en una imagen, se accederá a ella cuando tu navegador intente cargar la imagen:
1<img src="http://tubanco.com/transferir?a=mario&amt=2800">Debido a esto, siempre que estés construyendo una aplicación que puede aceptar algún cambio de estado, debería hacerse mediante una solicitud POST. Incluso si el banco requiere una solicitud POST, los campos de formulario ocultos aún pueden engañar a los usuarios para que envíen accidentalmente una solicitud. ¡El siguiente formulario ni siquiera espera a que el usuario haga clic; se envía automáticamente!
1<body onload="document.forms[0].submit()">2<form action="https://tubanco.com/transferir"3method="post">4 <input type="hidden" name="to" value="mario">5 <input type="hidden" name="amt" value="2800">6 <input type="submit" value="Click Aquí!">7</form>8</body>Lo anterior es un ejemplo de cómo podría verse Cross-Site Request Forgery (CSRF). Podemos detener ataques como estos creando un token CSRF al cargar una página web y luego solo aceptando formularios con un token válido.
¿Qué es lo que sigue?
Hemos discutido y visto muchos marcos web en esta clase, como Django y React, pero hay más marcos de desarrollo que podrían interesarte probar:
Lado del Servidor:
Lado del Cliente:
En el futuro, es posible que también desees poder implementar tu sitio en la web, lo cual puedes hacer a través de varios servicios:
Pueden dar un vistazo a la sección de cómo crear unabase de datos con Google Sheets, con React y Next.js más API routes.
¡Hemos recorrido un largo camino y cubierto mucho material desde el comienzo de este curso, pero aún hay mucho por aprender en el mundo de la programación web! Aunque a veces puede resultar abrumador, una de las mejores maneras de aprender más es sumergirse en un proyecto y ver hasta dónde puedes llegar con él. Creemos que en este punto tienes una base sólida en los conceptos de diseño web y que tienes lo necesario para convertir una idea en tu propio sitio web funcional. ¡Buena suerte en tus futuros proyectos! Si tienes más preguntas o necesitas ayuda con algo específico, no dudes en preguntar.
Mi feed...Feedback
Compartir en las redes:
2023 © NeoTecs · Hecho con 💖 porsolidSnk86
Todos los nombres de productos, logos y marcas son propiedad de sus respectivos creadores.